Desde tu primer documento hasta automatizar tu flujo de trabajo, sin conocimientos técnicos.
Antes de empezar
Qué hace Contextual Docs por ti
Contextual Docs lee tus documentos (facturas, contratos, albaranes, notas simples,
historias clínicas…), extrae los datos que te interesan y los
clasifica donde tú decidas. Te ahorras el trabajo manual de copiar y pegar.
Documentos caóticosPDFs, escaneos, Word, imágenes…
Contextual DocsLectura + extracción + clasificación con IA
Datos limpiosListos para Excel, tu CRM o tu API
Lo esencial
Empieza en 6 minutos
Tres pasos. Al terminar, ya estás extrayendo datos de tus documentos.
1
Sube tu primer documento
≈ 1 min
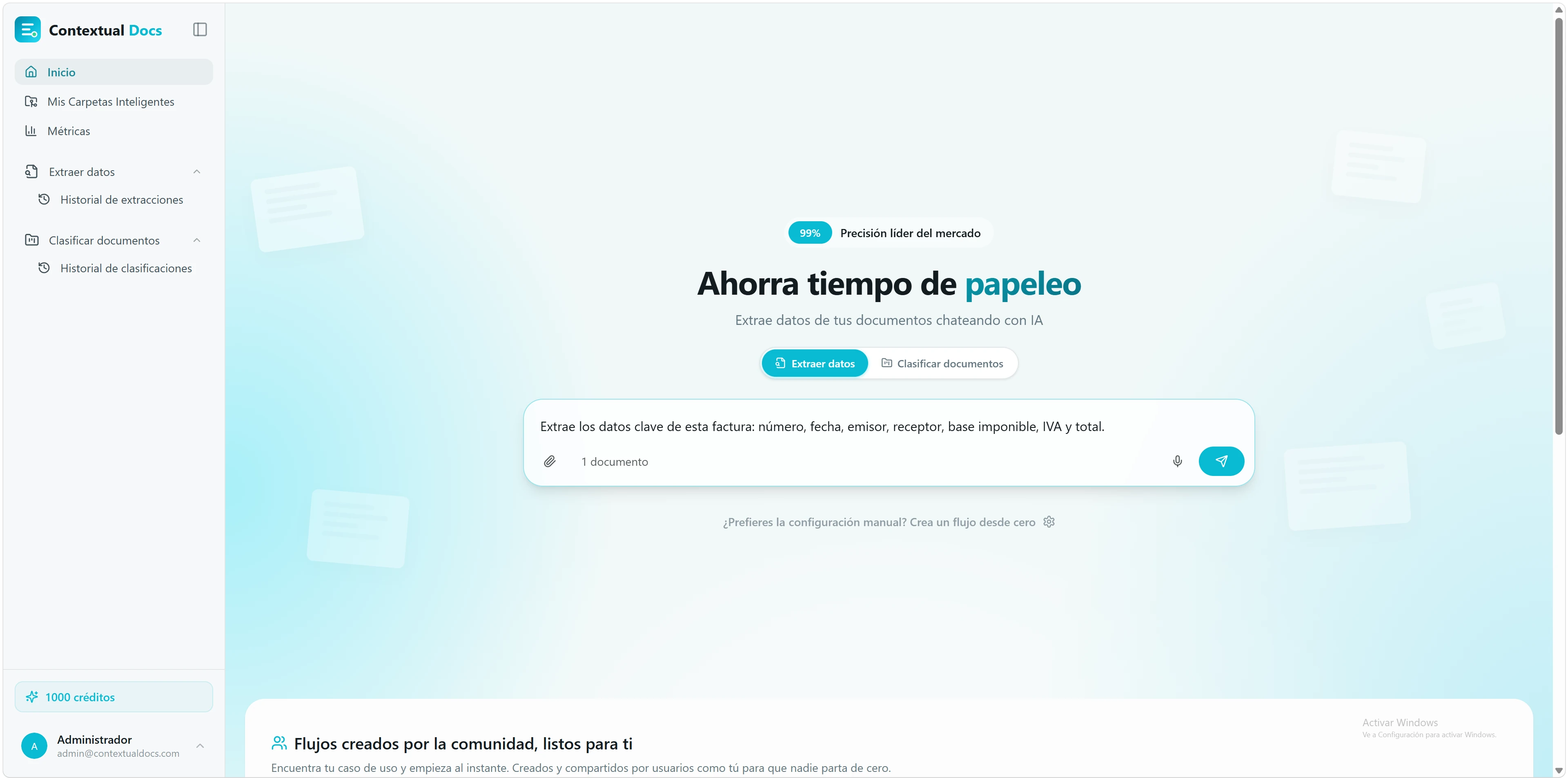
Todo empieza en la pantalla de inicio: un único campo donde dejas tu documento y escribes qué quieres sacar de él. Sin formularios, sin configurar nada antes.
Adjunta o arrastra el archivo. Pulsa el clip 📎 o arrastra el PDF o la imagen al campo del chat (de momento soportamos esos dos formatos). Puedes subir varios a la vez.
Explícale qué quieres extraer y cómo decidirlo. Piensa en cómo extraes hoy esos datos a mano y descríbelo en lenguaje natural. Incluye las reglas mentales que aplicas tú sin pensar — esas que la IA u otra persona no podrían adivinar si no se las cuentas. Por ejemplo: «extrae el total de la factura; si aparecen varios, quédate con el que incluye IVA», «sácame el NIF del proveedor, no el del cliente», «la fecha es la de emisión, no la de vencimiento».
Pulsa enviar. Contextual Docs analiza tu petición y genera al instante un flujo de extracción a medida — reutilizable y editable más adelante — que se ajusta exactamente a lo que has pedido. Te lleva al siguiente paso con ese flujo ya preparado para que lo confirmes o lo ajustes antes de lanzar la extracción.
Atajo útil: si ya usas un Excel o una plantilla donde metes estos datos a mano, hazle una captura a las cabeceras de las columnas y pégala en el campo del chat. Contextual Docs la interpreta y deduce qué campos quieres extraer, sin que tengas que escribirlos. Aun así, conviene añadir aparte tus reglas mentales para los casos ambiguos.
2
Confirma el flujo y lanza la extracción
≈ 2 min
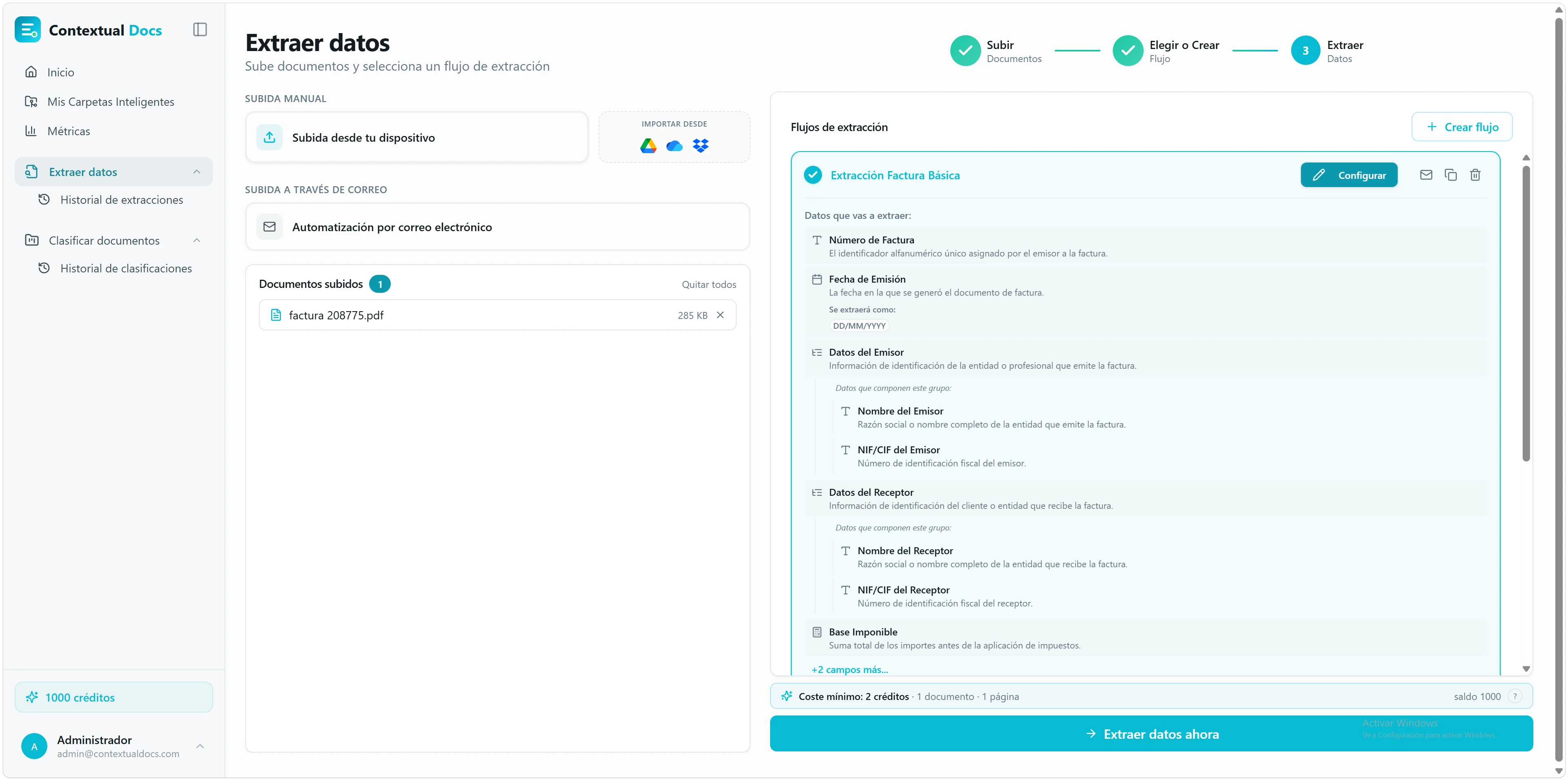
Contextual Docs te lleva al asistente de extracción. A la izquierda están los documentos que acabas de subir; a la derecha, el flujo de extracción que se ha creado a medida para tu petición, ya seleccionado.
Revisa la previsualización del flujo. En «Flujos de extracción», el flujo recién creado aparece ya seleccionado con una previsualización de los campos que va a extraer (por ejemplo: Número de Factura, Fecha de Emisión, Emisor, Receptor, Base Imponible, IVA y Total Factura). Despliega cada campo para ver su descripción y el formato esperado.
Configura, cambia o crea otro flujo. Pulsa «Configurar» en la tarjeta del flujo si quieres ajustar los campos o las reglas antes de lanzar. También puedes elegir otro flujo de la lista, usar uno de la comunidad o crear uno desde cero con «+ Crear flujo».
Pulsa «Extraer datos ahora». Verás un coste estimado en créditos según el número de páginas. Si ya procesaste antes el mismo documento, esas páginas no se vuelven a cobrar; el coste final depende del número de datos finalmente extraídos. La extracción dura unos segundos.
Los créditos se descuentan cuando el procesamiento termina sin errores — no cuando apruebas los datos. Si algo falla durante el procesamiento, no se cobra. Y los créditos del plan gratis dan para procesar unos cuantos documentos cada mes.
3
Revisa los datos extraídos
≈ 1 min
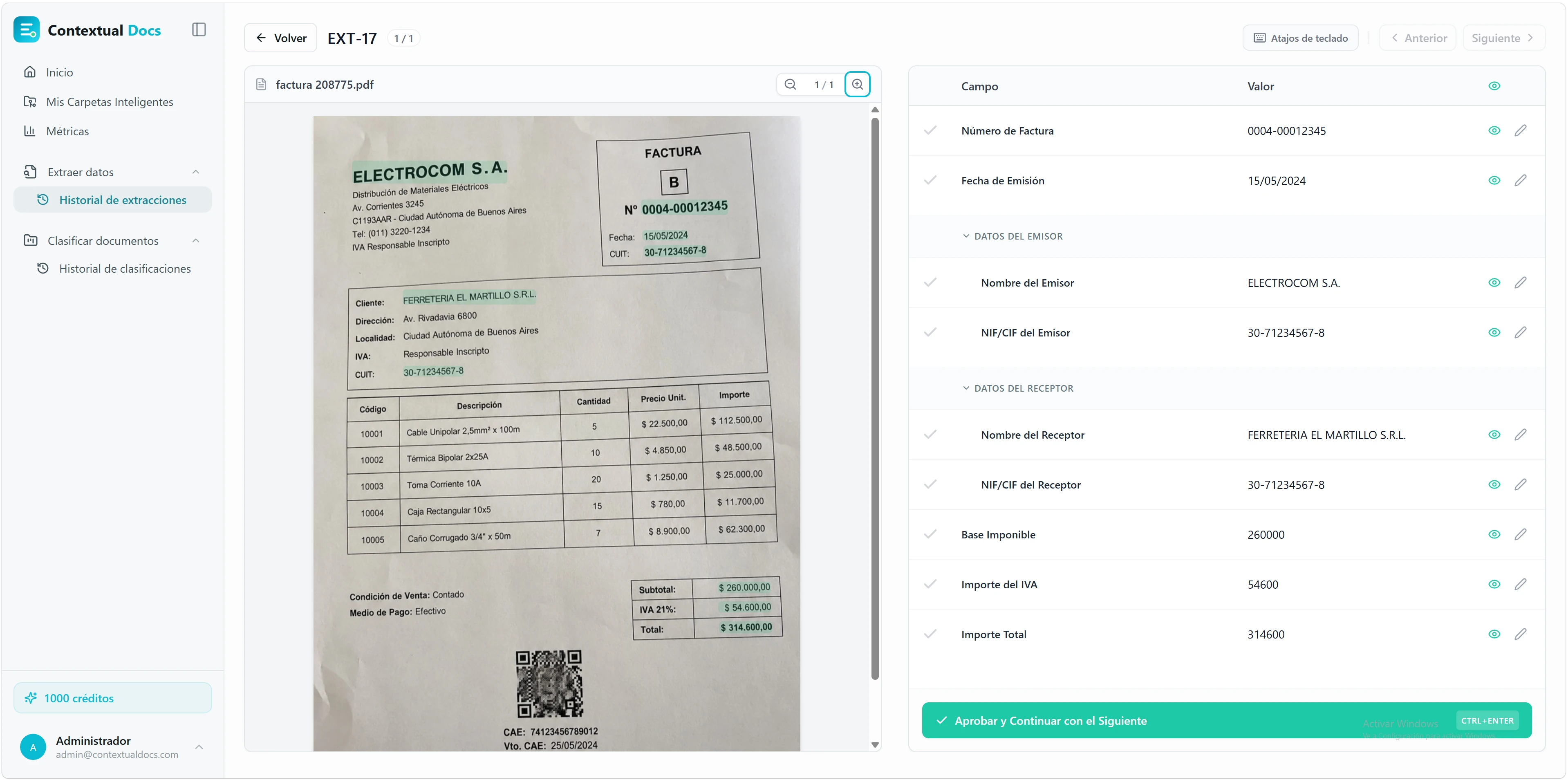
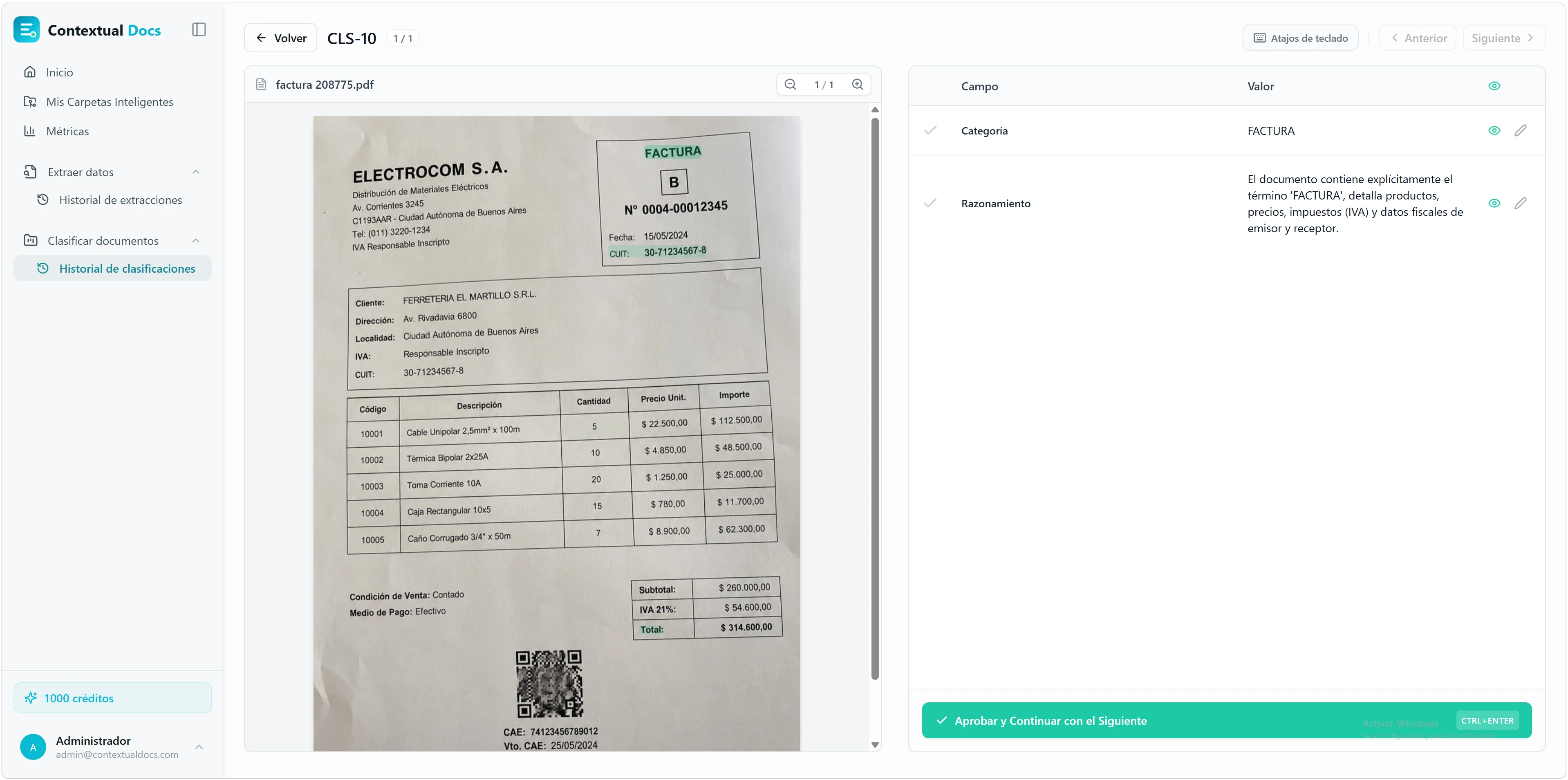
Aquí es donde tú validas lo que ha sacado la IA. La pantalla está dividida en dos: el documento original a la izquierda, los campos extraídos a la derecha. Comparas, corriges si hace falta y apruebas.
Haz clic en un campo y Contextual Docs te lo señala en el documento. Al seleccionar cualquier campo, el visor resalta automáticamente en verde de dónde lo ha sacado la IA en el PDF. Confirmas de un vistazo si es correcto, sin tener que buscarlo.
Edita lo que no esté bien. Si la IA se ha equivocado, haz clic en el valor del campo, corrígelo y pulsa Enter para saltar al siguiente. Tus cambios se confirman cuando apruebas el documento: hasta entonces puedes seguir ajustando.
Sabes qué has tocado y qué no. Cada campo lleva un check gris junto a su nombre mientras revisas; si editas un valor, ese check pasa a una aspa roja para que veas de un golpe de vista qué has modificado. Al aprobar el documento, todos los checks se ponen en verde.
Aprueba con un atajo. Cuando todo esté correcto, pulsa «Aprobar y Continuar con el Siguiente» o usa el atajo CTRL+ENTER (CMD+ENTER en Mac). Pasarás directo al siguiente documento del lote.
Revisa sin tocar el ratón: ↑/↓ para moverte entre campos, Enter para editar el campo seleccionado (otro Enter guarda y salta al siguiente), Escape para cancelar la edición, ←/→ para navegar entre documentos del lote y CTRL+ENTER (CMD+ENTER en Mac) para aprobar y pasar al siguiente. Tienes la chuleta completa siempre a mano en el botón «Atajos de teclado» de la propia pantalla de revisión. Con un poco de práctica, validar un documento te lleva segundos.
4
Clasifica documentos (en lugar de extraer datos)
≈ 2 min
Contextual Docs hace dos cosas con tus documentos: extraer datos y clasificarlos. El recorrido que acabas de hacer (subir → confirmar flujo → revisar) es idéntico para clasificación. Solo cambian tres detalles.
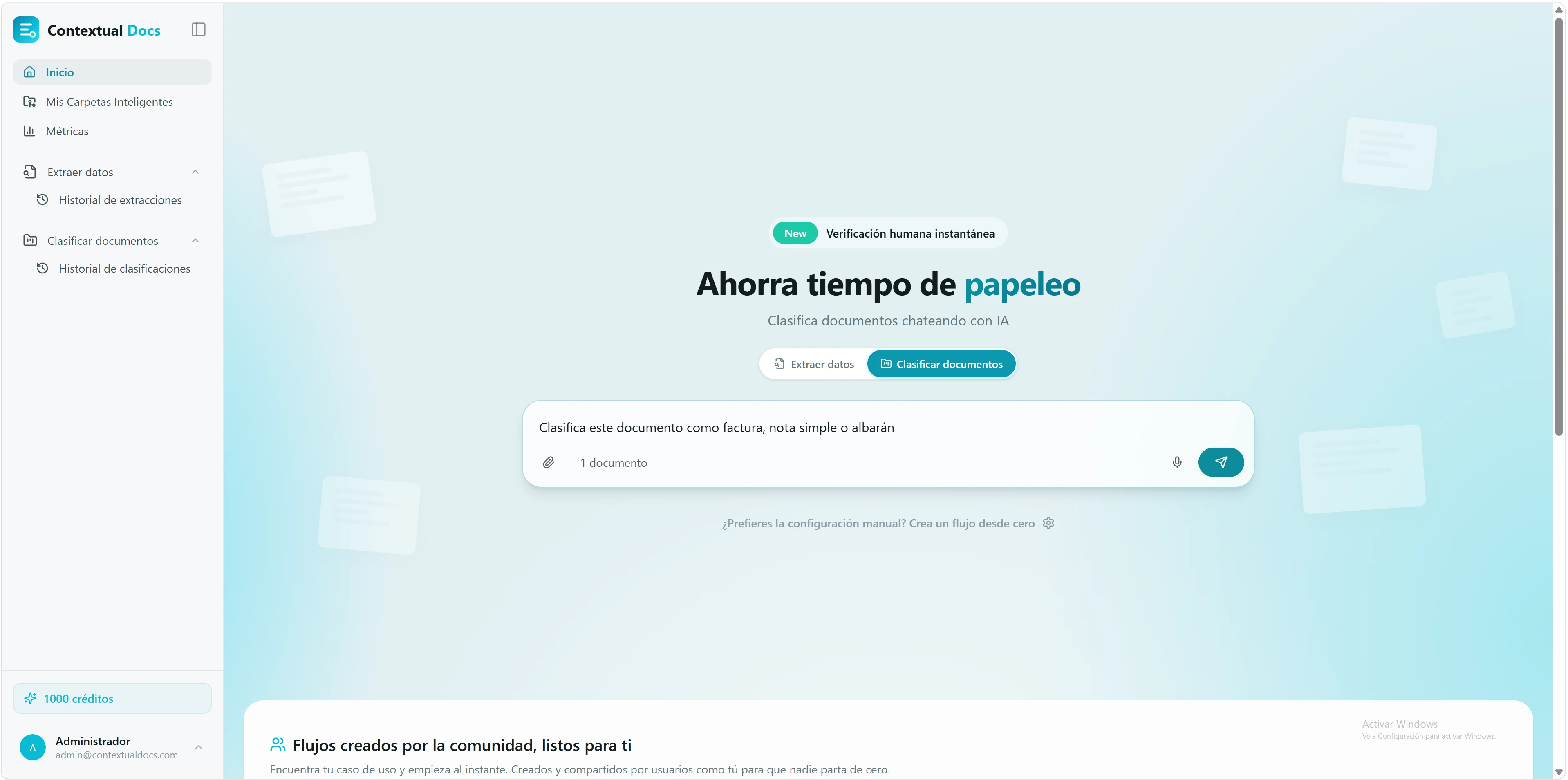
Cambia a la pestaña de clasificación. En la página de inicio, en lugar de «Extraer datos» pulsa «Clasificar documentos».
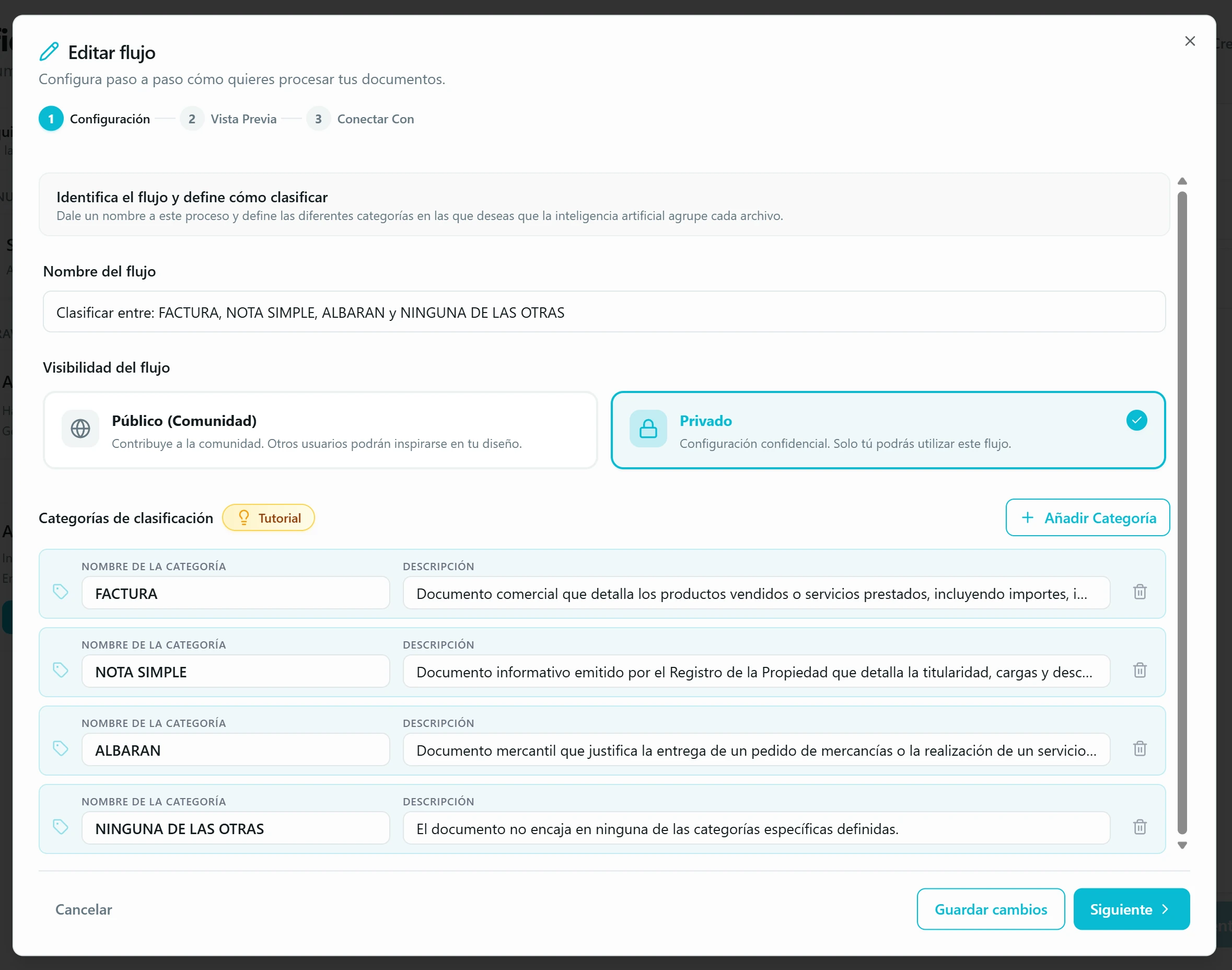
Le pides categorías, no campos. En vez de «extrae número, fecha y total», escribe algo como «clasifica este documento como factura, nota simple o albarán» — o por urgencia, por departamento, por cliente. Contextual Docs genera el flujo de clasificación correspondiente y te lo deja preseleccionado en el asistente.
Validas la categoría, no los valores. La pantalla de revisión es la misma que en extracción, pero en vez de comprobar valor por valor confirmas la categoría que la IA ha asignado al documento. Si está mal, la cambias y apruebas con CTRL+ENTER.
Lo realmente potente es combinar las dos: un flujo de clasificación decide el tipo de documento y, según la categoría, dispara automáticamente el flujo de extracción que toca. Lo enlazas en «Configurar → Conectar Con» del flujo de clasificación. Así, una factura recibe el tratamiento de factura y un albarán el de albarán sin que hagas ningún esfuerzo.
Cuando quieras escalar
Da el salto cuando lo básico ya fluya
Estos cuatro pasos son opcionales. Ábrelos cuando quieras procesar más volumen o conectar Contextual Docs con el resto de tu día a día.
5
Crea, refina y reutiliza tus Flujos
≈ 4 min
Si vas a procesar muchos documentos parecidos, no tienes que repetir el prompt: cada petición que haces queda guardada automáticamente como Flujo reutilizable. Lo refinas desde «Configurar» — un asistente de 3 pasos que controla todo lo que el flujo hace. Este paso cubre los dos primeros (Configuración y Vista Previa). Los detalles los desarrollamos sobre flujos de extracción; al final del paso tienes las equivalencias si el tuyo es de clasificación.
Crea un flujo nuevo o edita uno existente. En la página de Extraer datos o Clasificar documentos, pulsa «+ Crear flujo» y describe en el chat lo que quieres — Contextual Docs genera el flujo, lo deja guardado y te abre directamente su panel de Configurar. Si quieres editar un flujo ya creado, pulsa «Configurar» sobre su tarjeta.
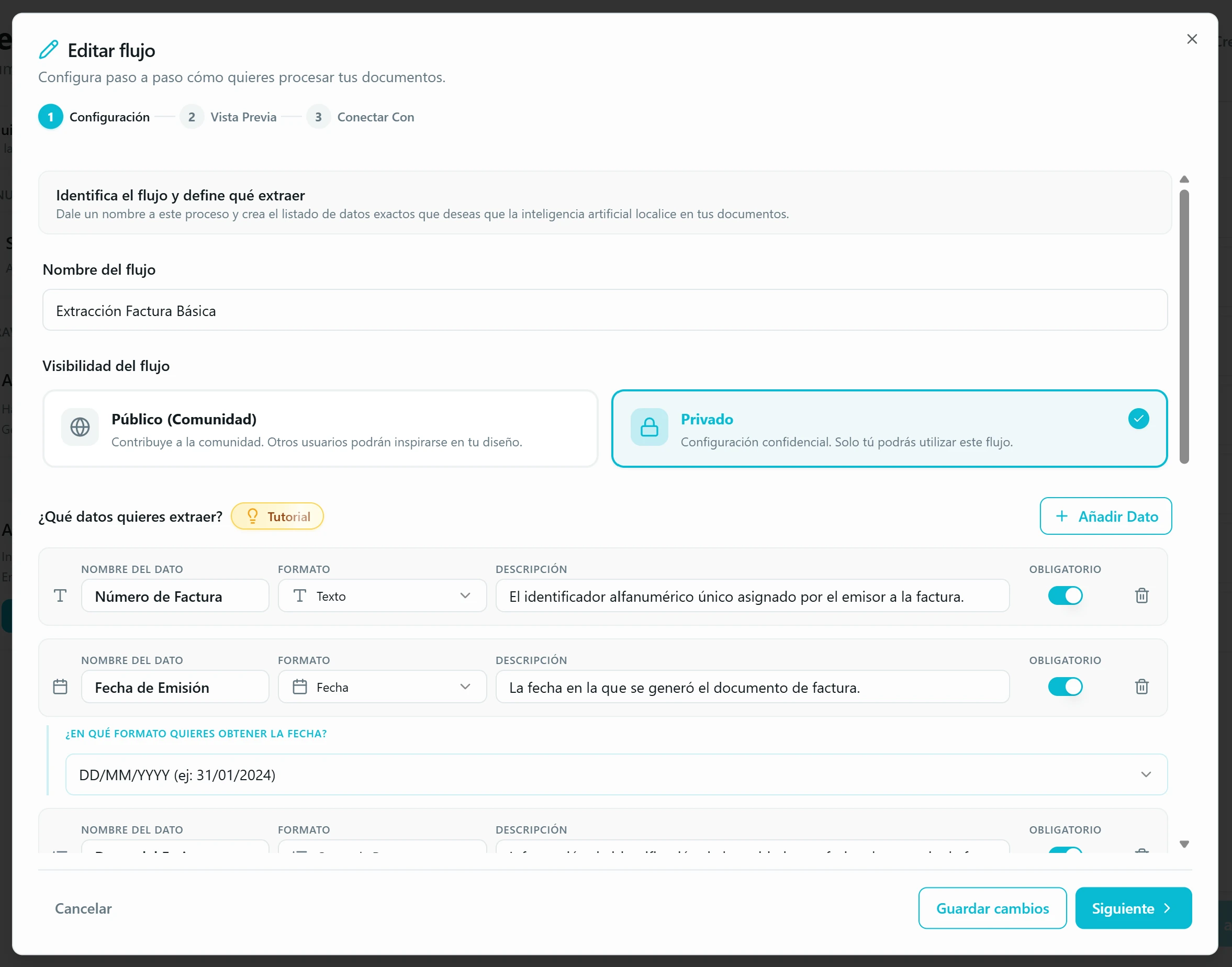
Configuración → datos del flujo. Ponle un nombre al flujo y decide si es Público (Comunidad) o Privado. La visibilidad determina si otros usuarios pueden reutilizarlo desde la comunidad o si se queda solo para ti.
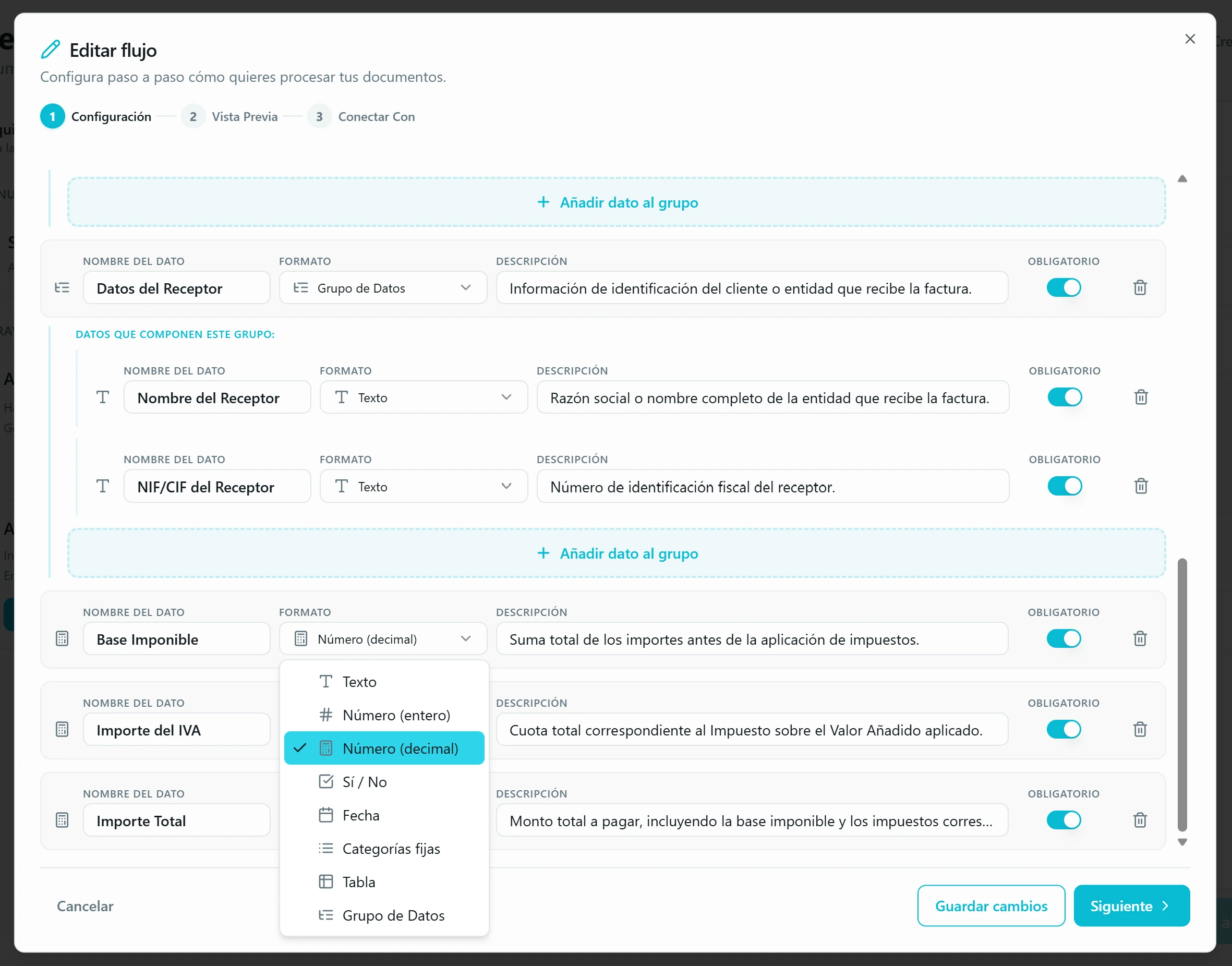
Configuración → datos a extraer. Por cada dato a extraer defines cuatro cosas. Nombre: corto y único — será la cabecera de tu columna en Excel. Formato: texto, fecha, número, categorías fijas, tabla, grupo… (lo desarrollamos en el siguiente punto). Descripción: aquí está el secreto del flujo. Es el prompt que la IA leerá ante cada documento, así que cuanto más concreta seas — qué buscar, dónde suele aparecer, en qué formato lo quieres, qué casos ignorar — mejor saldrá la extracción. Obligatorio: actívalo cuando el dato SIEMPRE deba aparecer en ese tipo de documento (número de factura, total, NIF del emisor…) y desactívalo para campos que pueden faltar legítimamente (dirección de envío opcional, descuentos, líneas de detalle no siempre presentes). Así la IA no se inventa valores cuando no encuentra el dato. Pasa el ratón por la pastilla dorada «Tutorial» (icono de bombilla) para abrir una guía con ejemplos buenos y malos.
Usa formatos inteligentes y estructuras complejas. Más allá del texto plano: «Categorías fijas» limita la respuesta a un conjunto cerrado (Soltero | Casado), «Fecha» fuerza un formato de salida («12 de Ene» → «12/01/2024»), «Tabla» captura elementos repetitivos (líneas de factura: Cantidad, Descripción, Precio) y «Grupo de Datos» anida campos relacionados como «Datos del Emisor».
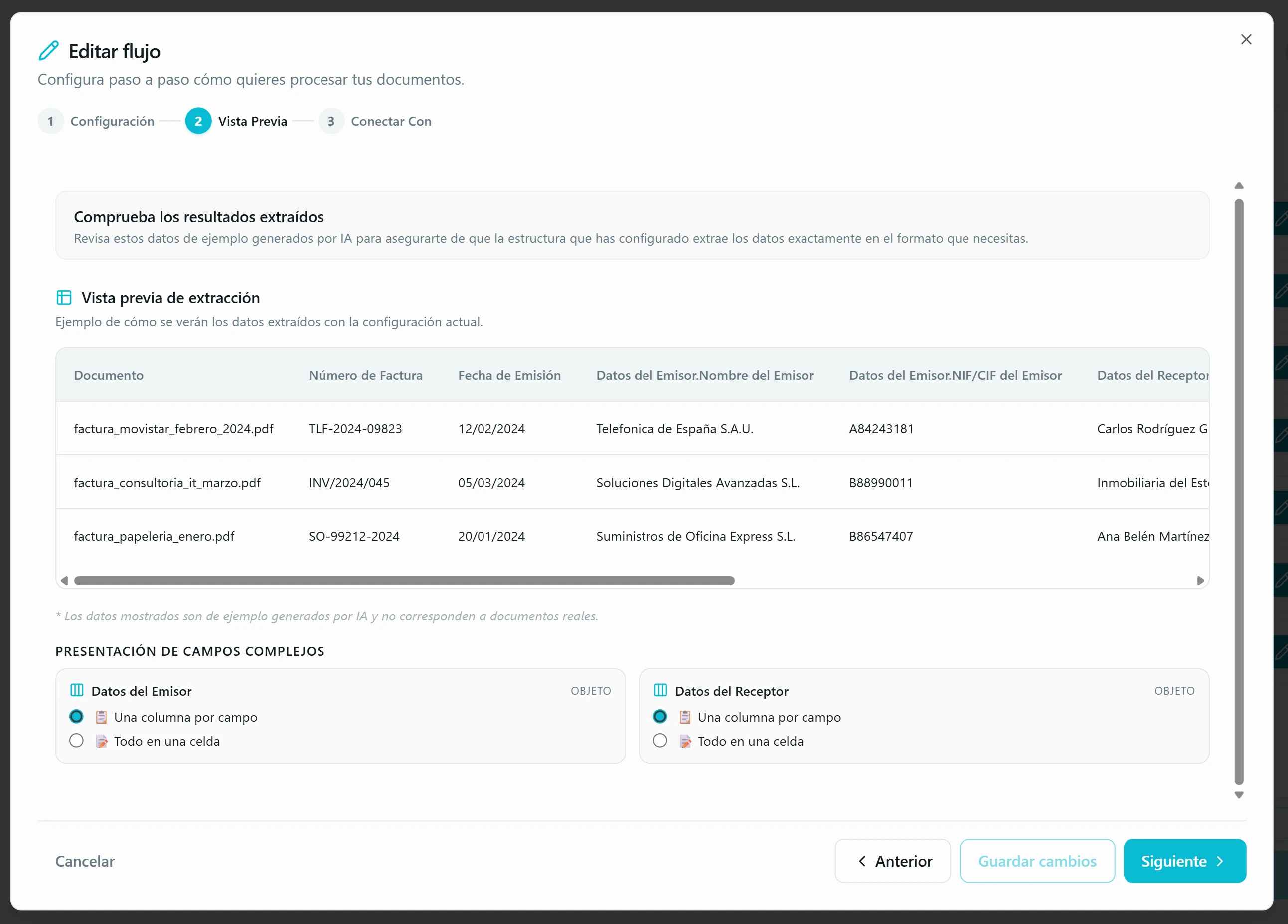
Vista Previa → simula antes de gastar créditos. La app genera una tabla de ejemplo con datos sintéticos sobre cómo quedaría la extracción con tu configuración. Si una columna sale rara, vuelves a Configuración y ajustas. Para los grupos, decides si quieres una columna por campo o todo en una sola celda.
Si tu flujo es de clasificación, las equivalencias. Donde aquí leíste «datos a extraer», en clasificación se llama «Categorías de clasificación»; para definir una categoría solo necesitas Nombre y Descripción — no hay formato ni Obligatorio, porque cada documento entra en exactamente una categoría. Los formatos inteligentes no aplican. La Vista Previa, en lugar de una tabla de columnas, te enseña a qué categoría asignaría documentos de ejemplo.
La «Descripción» de cada dato (o de cada categoría, si tu flujo es de clasificación) es donde está la diferencia entre un flujo malo y uno bueno. Compara: «Quiero la fecha» (extrae cualquiera) vs. «Fecha oficial de emisión en DD/MM/AAAA. Ignora fechas de pago. Suele estar en el encabezado» (extrae justo la que necesitas). Lo más detallado posible: ten en cuenta TODO lo que tú tienes en cuenta a la hora de decidir cuál es el valor a extraer (o, si tu flujo es de clasificación, en qué categoría encaja el documento).
6
Conecta tu flujo a destinos y encadénalo con otros
≈ 4 min
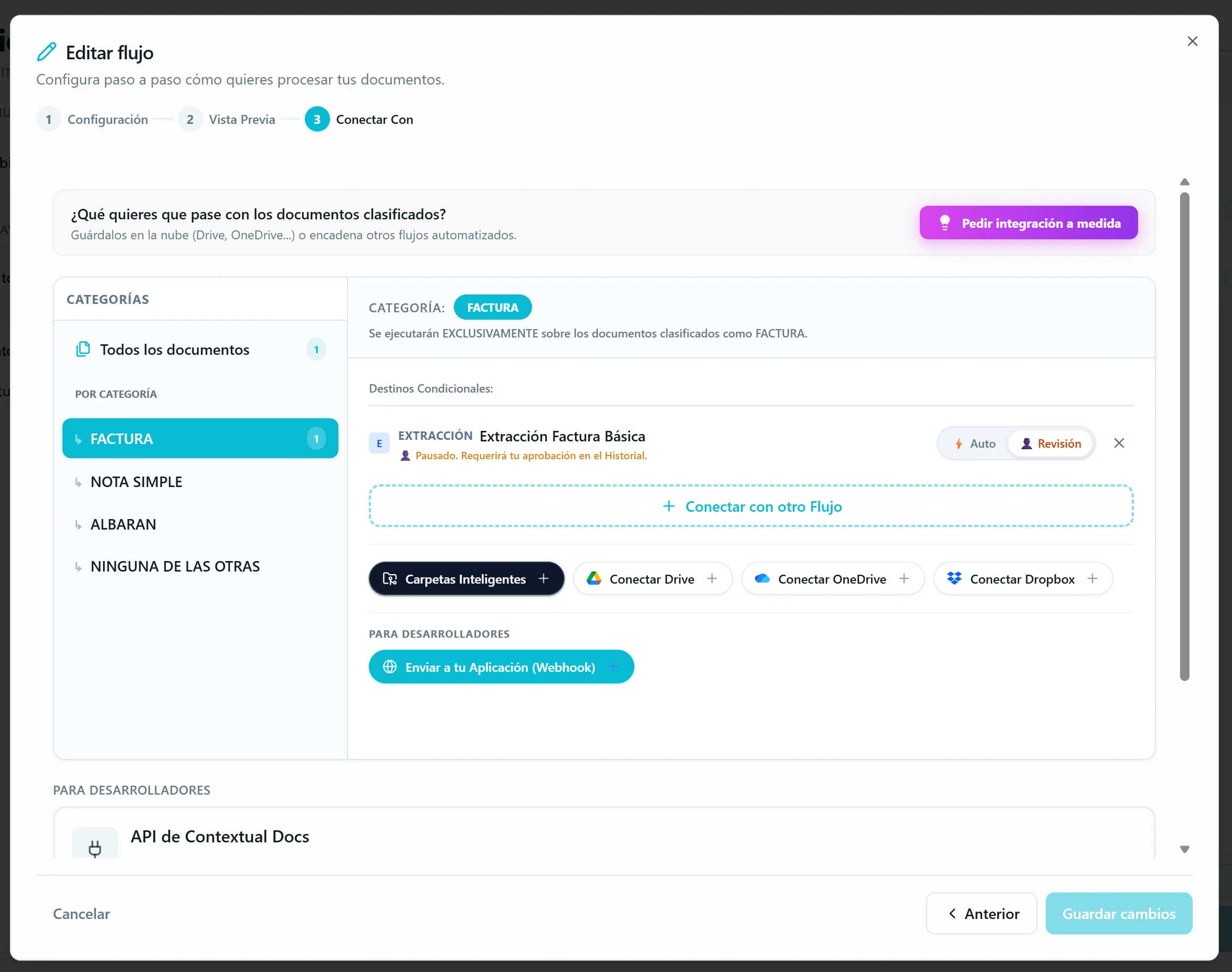
El tercer paso del Configurar de un flujo, «Conectar Con», es donde el flujo cobra vida: decides qué pasa con los datos una vez extraídos. Aquí es donde Contextual Docs deja de ser una herramienta de extracción manual y se convierte en automatización real.
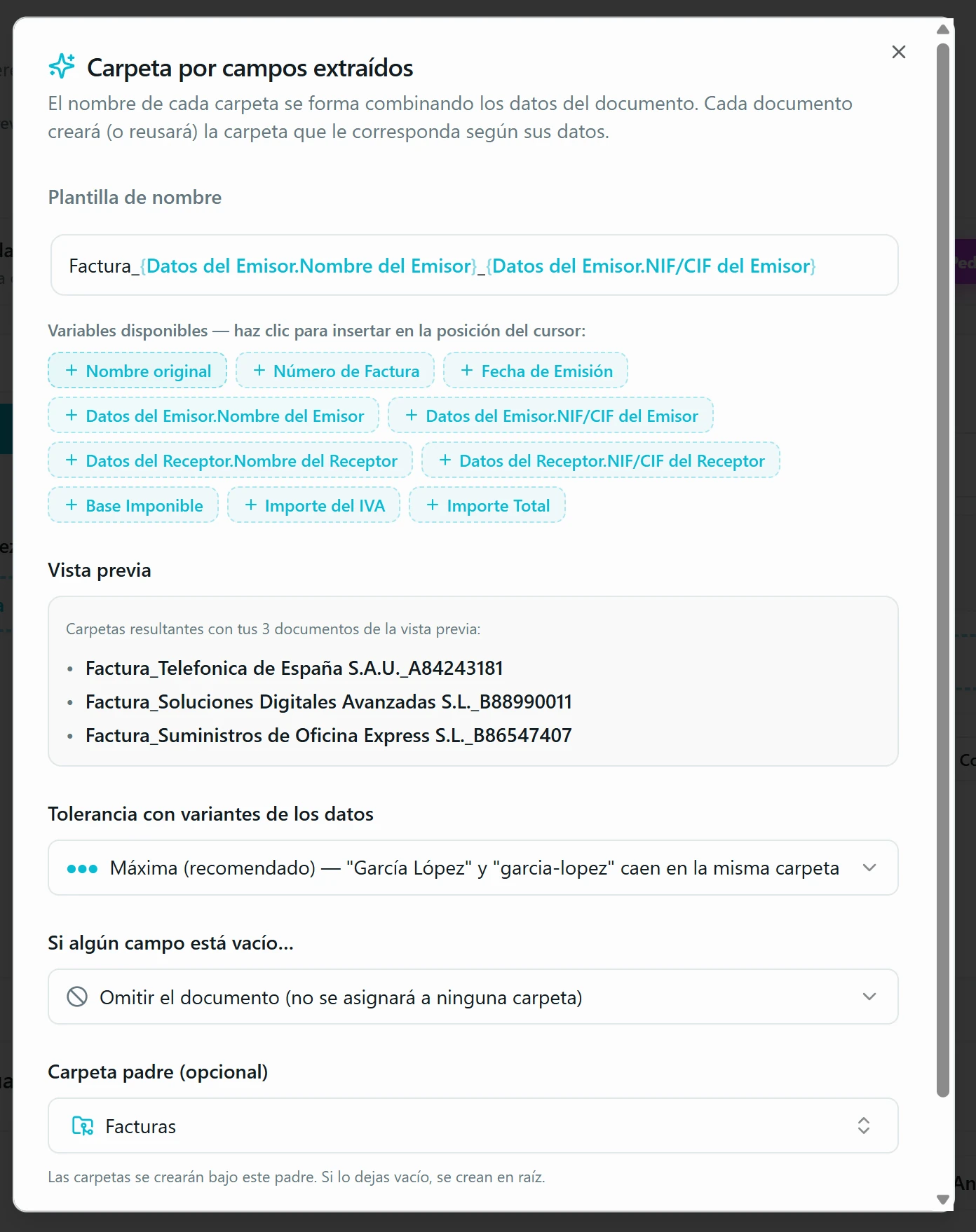
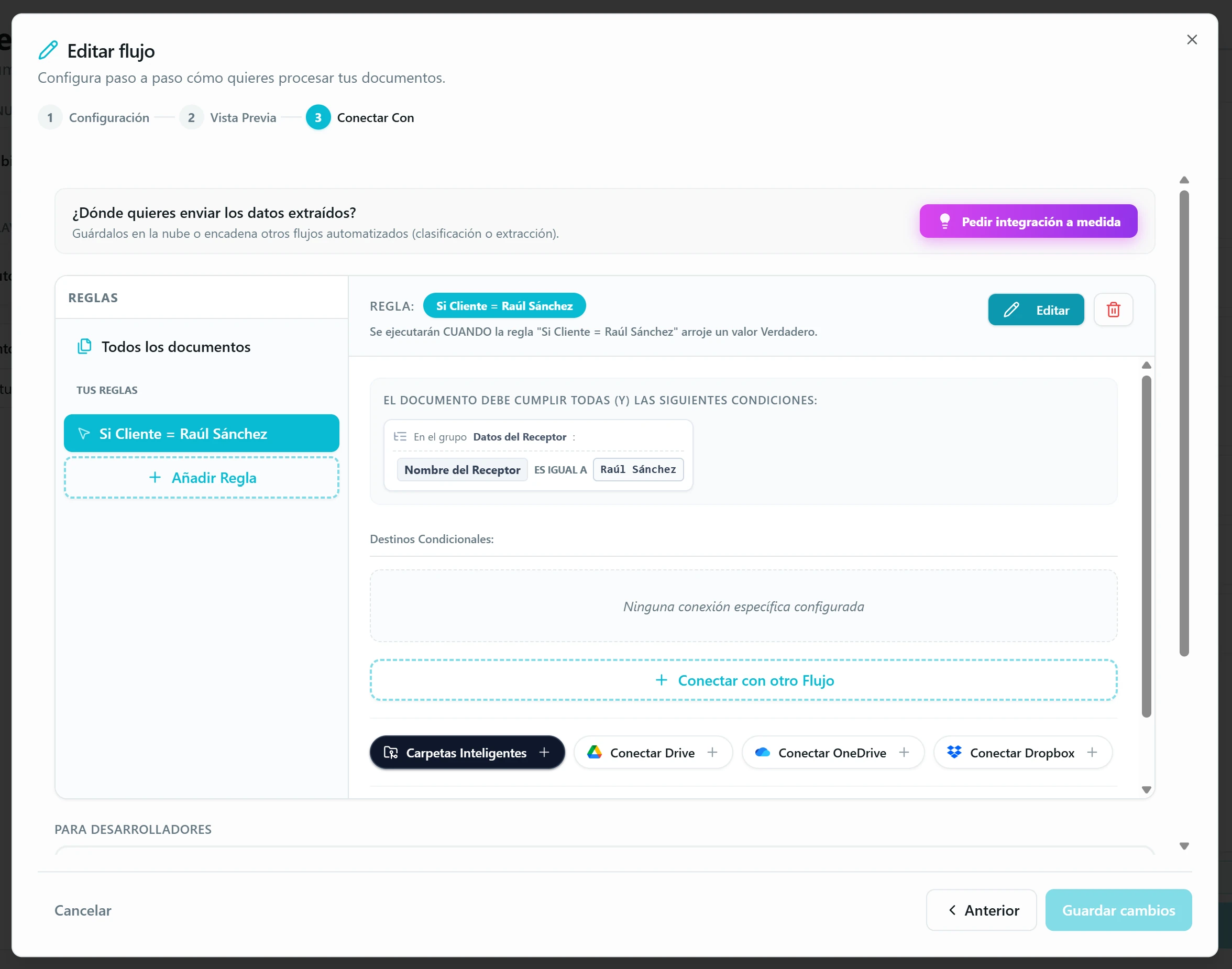
Aterriza los documentos en una Carpeta Inteligente. Tres modos. Carpeta concreta: todos los documentos van al mismo sitio. Carpeta por categoría (solo en flujos de clasificación): cada documento aterriza automáticamente en la carpeta de su tipo (facturas en «Facturas», nóminas en «Nóminas»…). Carpeta por campos extraídos: el nombre se genera con una plantilla del estilo «Factura_{Proveedor}» usando los datos que la IA acaba de sacar. La app crea la carpeta si no existe y reutiliza la que ya esté, con tolerancia a variantes («García López» y «garcia-lopez» caen en la misma) ajustable.
Encadena con otro Flujo. Aquí está la magia. Un flujo de clasificación decide el tipo del documento y, según la categoría, dispara el flujo de extracción que toca. O al revés: extraes datos y, según los valores extraídos, cada documento sigue su camino — encadena otro flujo, aterriza en una Carpeta Inteligente concreta, se sincroniza con una nube específica o dispara un webhook a tu aplicación. Las reglas que orquestan todo esto se definen en el punto 5 de esta sección. Es lo que monta pipelines completos sin código.
Sincroniza con Drive, OneDrive o Dropbox. Si quieres que los documentos procesados acaben también en la nube del equipo, conecta una de las tres integraciones de almacenamiento desde esta misma pestaña.
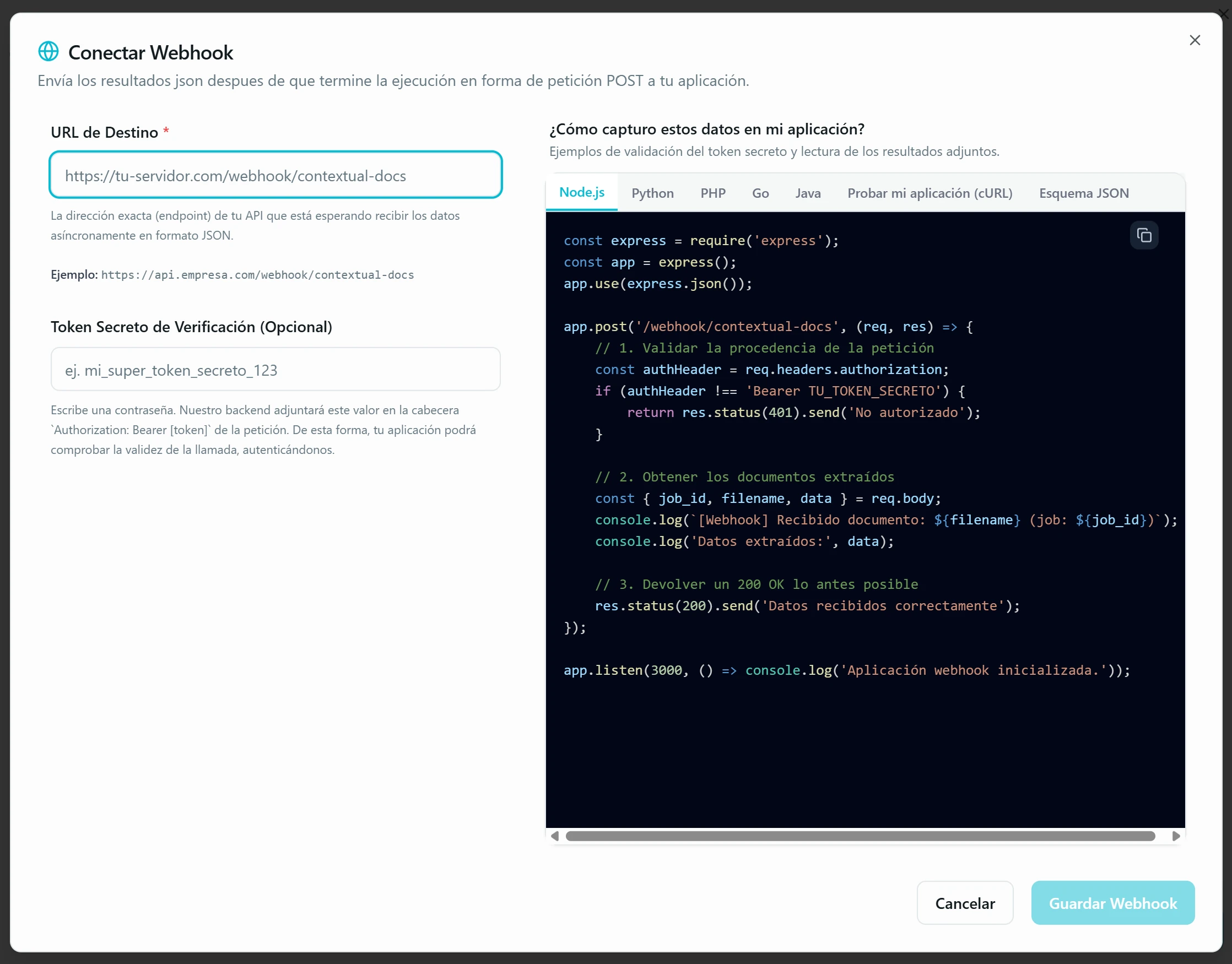
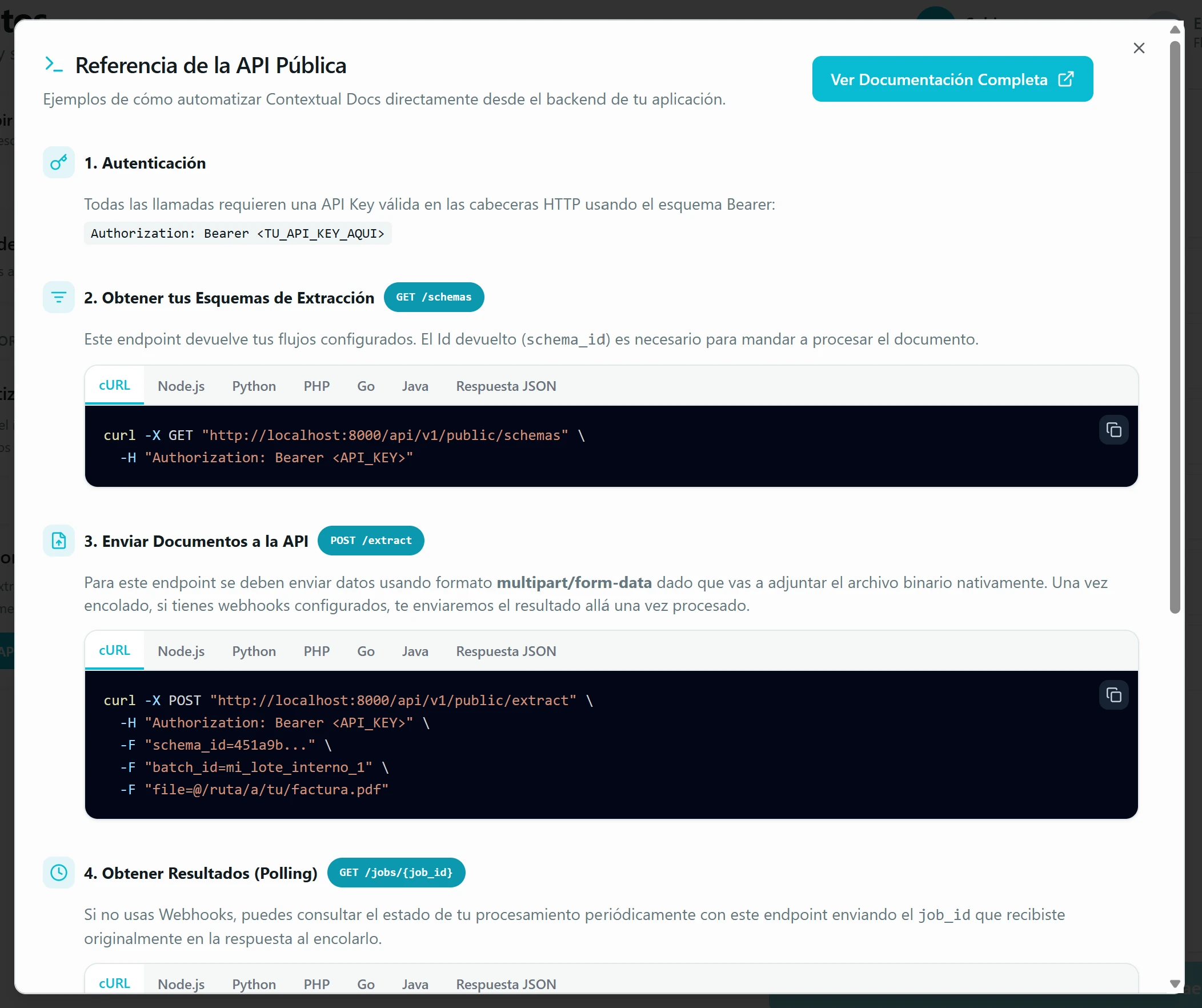
Envía a tu aplicación vía Webhook. Tu backend recibe un POST con los resultados en JSON, autenticado con un token secreto que tú defines (Authorization: Bearer). La ventana incluye ejemplos de código listos para copiar en Node.js, Python, PHP, Go, Java y cURL, más una pestaña con el esquema JSON del payload para que tu equipo pueda tipar el endpoint receptor. Cada aviso llega con un campo event que indica su tipo: created (primer envío del documento), data_corrected (alguien corrigió los datos tras revisarlos y te reenviamos los valores nuevos) y connection_removed (tras una corrección, el documento ya no cumple la regla que disparaba el envío). Con el execution_id como clave puedes casar los tres eventos en tu base de datos y mantenerla siempre sincronizada con lo que validan las personas; cada aviso incluye además sent_at (momento de emisión) para que, ante reintentos o avisos muy seguidos, te quedes con el más reciente y descartes duplicados.
Crea reglas condicionales para destinos distintos. Por defecto los destinos aplican a «Todos los documentos», pero puedes añadir reglas (por ejemplo, «Si el Cliente es Raúl Sánchez») que envían ciertos documentos a sitios distintos según el valor de un campo extraído. Combinable con todo lo anterior.
Si tu flujo es de clasificación, las equivalencias. Donde aquí leíste «Reglas» (punto anterior), en clasificación son directamente las propias Categorías: cada categoría detectada puede tener sus propios destinos sin necesidad de definir condiciones — el tipo del documento ya es la condición. El resto (Carpetas Inteligentes, encadenar flujos, sincronización con la nube y Webhook) funciona idéntico.
¿Echas en falta una integración con un sistema concreto (ERP, CRM, herramienta interna)? Pulsa «Pedir integración a medida» en la cabecera de la pestaña. Lo evaluamos y te respondemos.
7
Organiza tus documentos en Carpetas Inteligentes
≈ 2 min
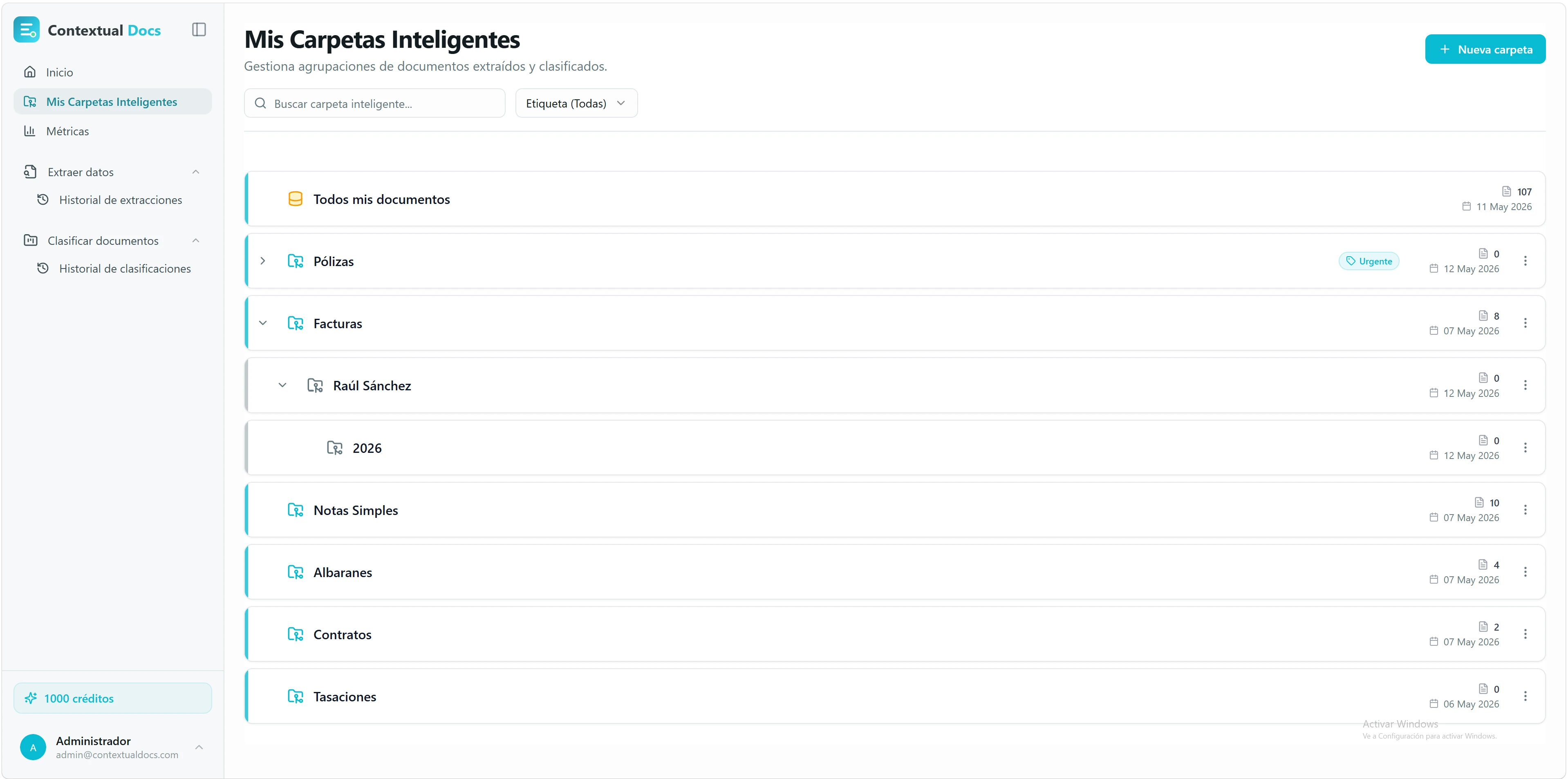
Una vez extraídos los datos, ¿dónde guardas los documentos? En Carpetas Inteligentes. Son agrupaciones tuyas, con jerarquía y etiquetas, para que encuentres cualquier cosa en segundos.
Crea carpetas con jerarquía. Hasta 5 niveles de profundidad. Por ejemplo: Facturas → 2026 → Q1 → Proveedor X.
Etiqueta tus carpetas. Añade etiquetas (tags) a cualquier carpeta — «urgente», «revisado», «cliente A»… — y filtra por ellas en el listado para encontrar al vuelo lo que buscas.
Los documentos llegan solos. Cada documento procesado aterriza automáticamente en la Carpeta Inteligente que le toque, según los destinos que configuraste en «Conectar Con» (paso 6). Sin archivar a mano: tú configuras una vez y todos los documentos siguientes se ordenan solos en su carpeta.
Reorganiza cuando lo necesites. Puedes mover una carpeta entera de sitio dentro de la jerarquía (con sus subcarpetas y documentos), renombrarla o eliminarla. Si tu negocio cambia o ves que la organización inicial se queda corta, la rehaces sin tener que volver a procesar nada.
8
Automatiza la entrada
≈ 3 min
Más allá del botón de subir, tienes varios caminos para que los documentos lleguen a Contextual Docs. Algunos te ahorran clicks puntuales; otros automatizan la entrada de verdad.
Importa desde Drive, OneDrive o Dropbox. Cuando subas documentos a un flujo, puedes elegirlos directamente desde tu nube en lugar de bajarlos antes a tu equipo. Conexión un clic con cada proveedor.
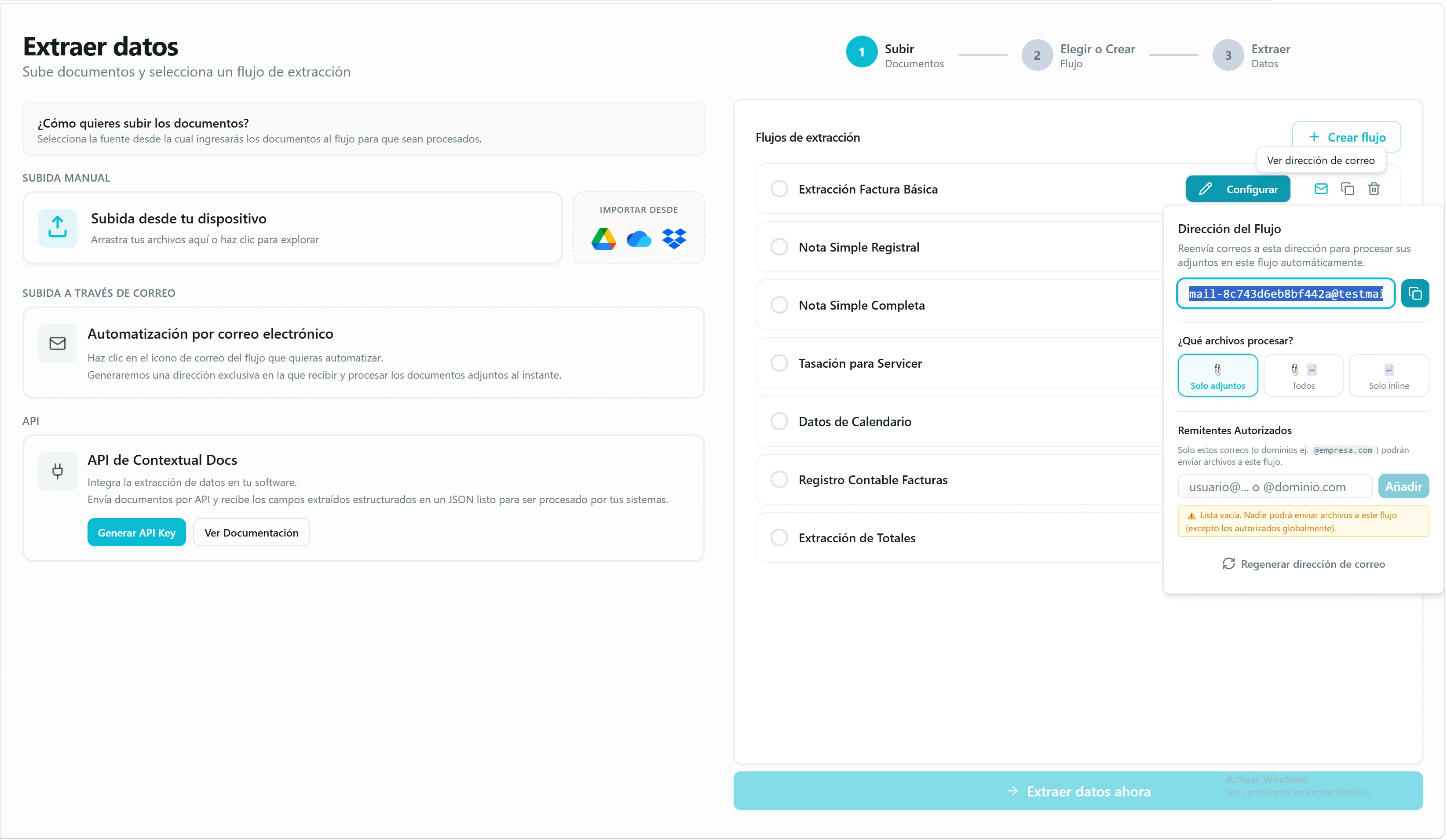
Activa la entrada por email. En la tarjeta del flujo pulsa el icono de sobre y dale a «Activar correo para este flujo»: Contextual Docs genera al instante una dirección única para ese flujo. Reenvía a esa dirección o pide a tus proveedores que envíen sus documentos ahí — los adjuntos se procesan al recibirse, sin tocar la app. Por seguridad, en la misma ventana defines los Remitentes Autorizados (correos sueltos como juan@empresa.com o dominios enteros como @empresa.com) que pueden mandar al flujo; el resto se ignora. Si prefieres autorizar a todo tu equipo de una vez para cualquiera de tus flujos, hazlo desde Ajustes → Seguridad → Acceso por correo. Es el camino más automático de los cuatro apartados de esta sección.
Sube vía API REST. Si tienes un ERP, un CRM o un backend propio, súbele documentos a procesar con POST /api/v1/public/extract (multipart/form-data: tu archivo + el schema_id del flujo, que obtienes con GET /schemas). Recoges los resultados de dos formas, a tu elección: por polling sobre GET /jobs/{job_id} con el id que devuelve el extract, o por webhook si configuraste uno en el flujo (sección 6) — en ese caso te llegan empujados al endpoint que indicaste en cuanto el job termina. Tienes la referencia completa con ejemplos en cURL/Node/Python/PHP/Go/Java en la ventana «Referencia de la API Pública» dentro de la app.
Orquesta con Make, Zapier o n8n. No tenemos conectores nativos publicados, pero al exponer una API REST (apartado 3) estándar puedes orquestarla desde cualquiera de ellos con un nodo HTTP genérico. Cualquier paso «antes» (preparar el documento) o «después» (mover el resultado a tu sistema) cabe ahí, sin escribir código de servidor.
9
Saca los datos donde los necesites
≈ 1 min
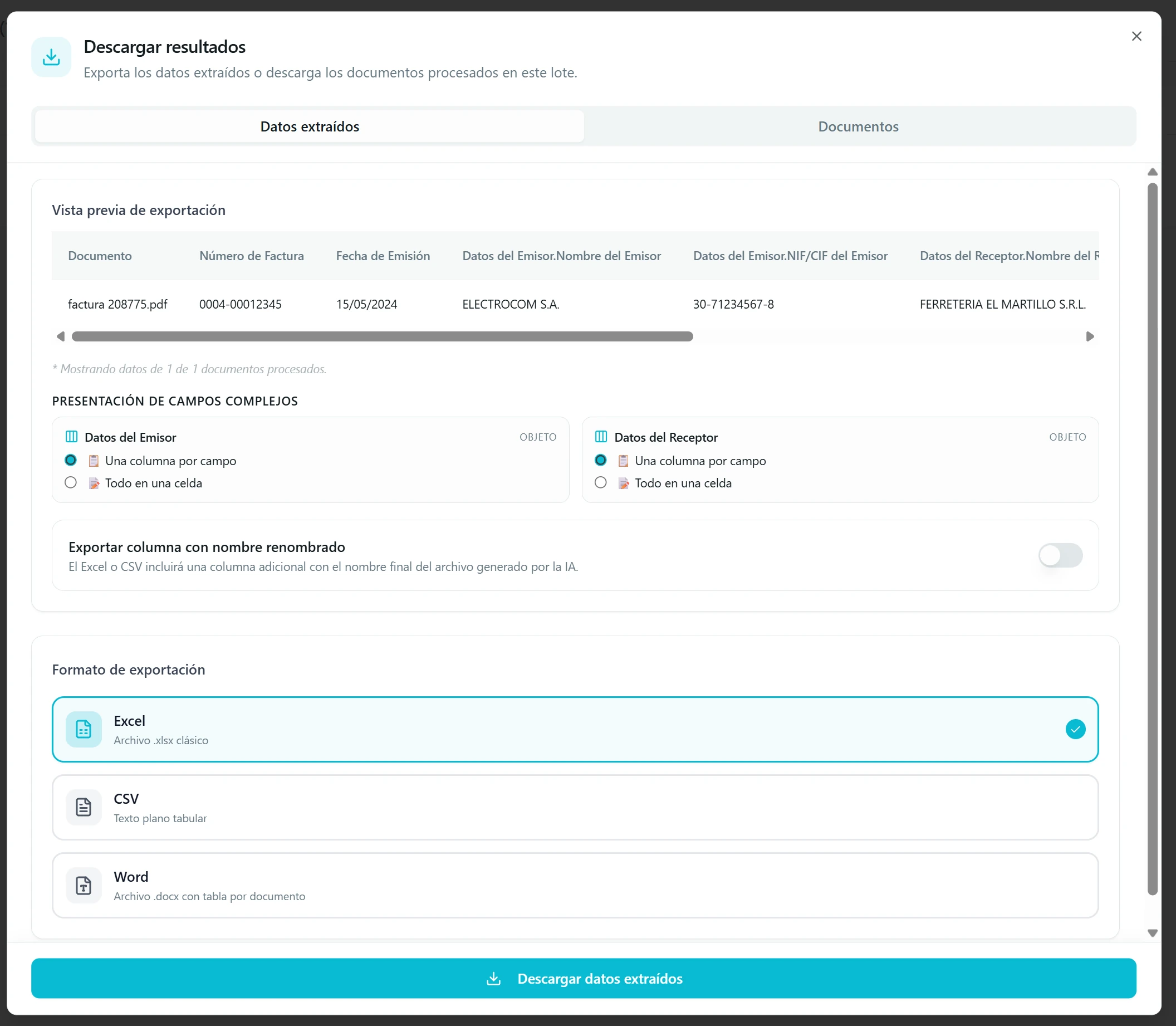
Aparte de los destinos automáticos que ya configuraste en «Conectar Con» (paso 6), siempre puedes bajarte los datos a tu equipo en el formato que tu hoja de cálculo o tu sistema esperen. El botón «Descargar resultados» del historial de extracciones abre una ventana con dos pestañas: una para los datos extraídos y otra para los documentos originales.
Pestaña Datos: Excel, CSV o Word. Eliges el formato que mejor encaje con tu sistema: Excel (.xlsx), CSV (con el separador que tu hoja entienda — coma, punto y coma, barra, tabulador o uno personalizado) o Word (.docx). Tanto en Excel como en CSV puedes incluir una columna adicional con el nombre renombrado del documento según la plantilla del flujo.
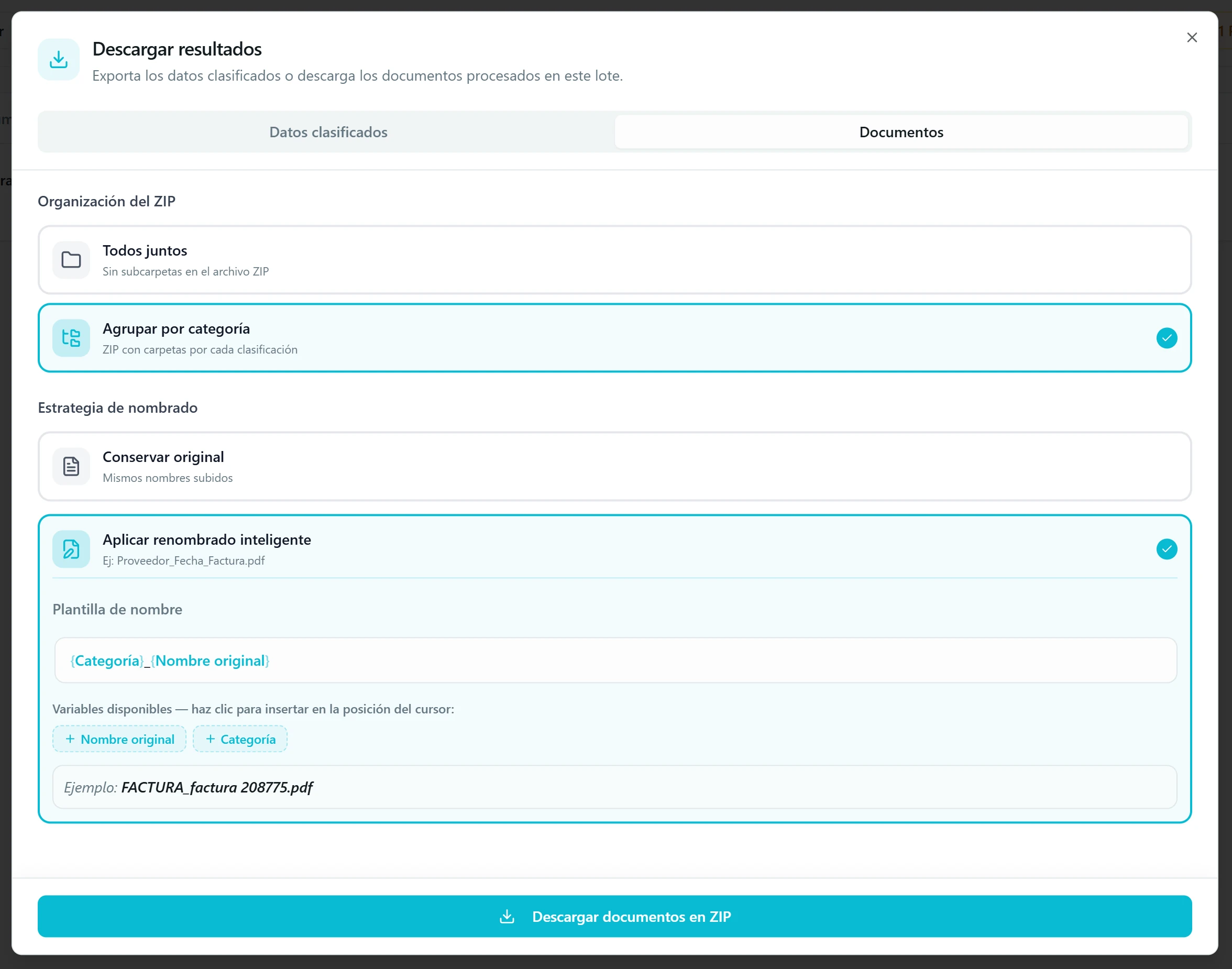
Pestaña Documentos: los archivos originales en ZIP. Te llevas también los documentos procesados, no solo sus datos. Decides si los nombres van originales o renombrados con la información que la IA acaba de extraer: en flujos de extracción usa los datos extraídos (ej. Factura_2026-05-12_AcmeSA.pdf), en clasificación usa la categoría asignada (ej. Factura_documento-original.pdf). Si es un flujo de clasificación, eliges además si el ZIP va plano (todo junto) o agrupado por categorías en subcarpetas.
Salida automática: ya está montada. Si lo tuyo es que la salida pase sola — Carpeta Inteligente, Drive/OneDrive/Dropbox, webhook a tu sistema — eso lo configuraste en la sección 6 («Conectar Con») y se dispara cada vez que apruebas un documento. No tienes que bajarte nada a mano.
Ayuda
Preguntas frecuentes
¿Necesito saber programar?
No. Toda la app está pensada para usarse sin conocimientos técnicos: subes el documento, escribes qué quieres en español normal y la IA hace el resto. Solo la parte de API y webhooks (opcional) está pensada para equipos de IT.
¿Qué tipos de documento puedo subir?
De momento, PDFs (escaneados o nativos) e imágenes en PNG, JPG y WebP. Si el PDF es escaneado o estás subiendo una imagen, Contextual Docs aplica OCR automáticamente para leer el texto. Word y Excel todavía no están soportados directamente; si necesitas procesar uno, expórtalo a PDF antes de subirlo.
¿Tengo que crear una Carpeta Inteligente antes de empezar?
No. Puedes empezar a procesar documentos desde la pantalla de inicio sin crear nada. Las Carpetas Inteligentes son agrupaciones tuyas con jerarquía y etiquetas, donde los documentos procesados aterrizan automáticamente según los destinos que configures en sus flujos. Lo procesado siempre está accesible en el historial aunque no tengas ninguna; las creas cuando quieras dar un orden propio y filtrar después con un par de clics.
¿Qué pasa si la IA se equivoca?
Tú revisas cada campo antes de aprobar y lo corriges si hace falta — los datos finales quedan exactamente como tú los dejas. Si ves que la IA se equivoca en el mismo tipo de campo varias veces, abre «Configurar» y afina la descripción de ese campo (añade reglas, ejemplos o casos a ignorar): así mejoras la extracción/clasificación para los siguientes documentos.
¿Puedo editar un Flujo después de crearlo?
Sí, siempre. Pulsa «Configurar» sobre la tarjeta del Flujo y ajusta nombre, campos, descripciones, formatos o destinos en cualquier momento. Los cambios se aplican a las extracciones/clasificaciones que lances a partir de ese momento; lo que ya procesaste y aprobaste se queda como estaba.
¿Puedo subir varios documentos a la vez?
Sí. Arrastra o adjunta varios PDFs o imágenes al campo del chat y se procesan en lote. El tamaño máximo del lote depende de tu plan — los planes superiores permiten lotes más grandes; consulta el detalle en Precios. Después los revisas uno a uno con los atajos de teclado (CTRL+ENTER en Windows, CMD+ENTER en Mac — aprueba y salta al siguiente). Si tu volumen es grande y recurrente, conecta un correo o vía API REST (apartado 8) para que los documentos entren solos sin tener que subirlos a mano.
¿Puedo procesar documentos en idiomas distintos al español?
Sí. La IA reconoce documentos en los principales idiomas europeos. Las descripciones de los campos del Flujo puedes escribirlas en español aunque el documento esté en otro idioma — la extracción funciona igual. Incluso puedes decidir en qué idioma quieres que se extraigan los datos (p. ej. documento en francés y resultado en español, o al revés).
¿Listo para probar?
Crea tu cuenta gratis y procesa tus primeros documentos en minutos. Sin tarjeta.
Sube tu primer documento gratis. Sin tarjeta. Sin instalación.
Plan gratis para siempre Verificación humana incluida Datos en la UE
Usamos cookies para que el sitio funcione y, con tu consentimiento, para entender cómo se usa. Política de cookies.
Preferencias de cookies
Activa o desactiva las categorías. Las cookies estrictamente necesarias no se pueden desactivar porque son imprescindibles para el sitio. Más detalle en la Política de cookies.
Estrictamente necesarias
Recuerdan tu elección de cookies para que no te volvamos a preguntar. No se pueden desactivar.
Siempre activas
Ver proveedores y cookies
Cookie
Proveedor
Finalidad
Duración
cd_consent
contextualdocs.com
Almacena tu elección sobre las categorías de cookies.
12 meses
Analíticas
Google Analytics 4 (con IP anonimizada) y Microsoft Clarity para medir el uso agregado del sitio.
Ver proveedores y cookies
Cookie
Proveedor
Finalidad
Duración
_ga, _ga_*
Google Analytics 4 (Google Ireland Ltd.)
Identificador agregado para distinguir visitantes y medir uso del sitio. IP anonimizada.
Hasta 24 meses
_clck, _clsk
Microsoft Clarity (Microsoft Ireland Operations Ltd.)
Mapas de calor y grabaciones de la navegación (clics, desplazamiento y cursor) con enmascarado automático del texto, para detectar problemas de usabilidad.
Hasta 12 meses
Transferencia internacional cubierta por Cláusulas Contractuales Tipo y EU-U.S. Data Privacy Framework. Detalle en la Política de cookies.